DP-800 Reliable Dumps Questions, DP-800 Study Guides
Wiki Article
To practice for a Developing AI-Enabled Database Solutions in the software (free test), you should perform a self-assessment. The Microsoft DP-800 practice test software keeps track of each previous attempt and highlights the improvements with each attempt. The Microsoft DP-800 Mock Exam setup can be configured to a particular style & arrive at unique questions.
Good opportunities are always for those who prepare themselves well. You should update yourself when you are still young. Our DP-800 study materials might be a good choice for you. The contents of our DP-800 learning braindumps are the most suitable for busy people. And we are professional in this field for over ten years. Our DP-800 Exam Questions are carefully compiled by the veteran experts who know every detail of the content as well as the displays. Just have a try and you will love them!
>> DP-800 Reliable Dumps Questions <<
DP-800 Study Guides | Training DP-800 Kit
Provided that you lose your exam with our DP-800 exam questions unfortunately, you can have full refund or switch other version for free. All the preoccupation based on your needs and all these explain our belief to help you have satisfactory and comfortable purchasing services on the DP-800 Study Guide. We assume all the responsibilities our DP-800 simulating practice may bring you foreseeable outcomes and you will not regret for believing in us assuredly.
Microsoft Developing AI-Enabled Database Solutions Sample Questions (Q115-Q120):
NEW QUESTION # 115
Drag and Drop Question
You have an Azure SQL database named sqldb-ai-prod that stores customer support tickets for a multitenant software as a service (SaaS) application. sqldb-ai-prod contains a table named Tickets. Tickets contains columns named TenantId, TicketId, CustomerEmail, CustomerPhone, and Notes.
You plan to harden data access, since a new support team will use ad hoc reporting tools that connect directly to sqldb-ai-prod.
You need to configure security to meet the following requirements:
- Support agents must see only the rows of their own TenantId column.
- Support agents must see only the domain name portion of the
CustomerEmail column.
What should you do for each requirement? To answer, drag the appropriate actions to the correct requirements. Each action may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 116
Hotspot Question
You have a SQL database in Microsoft Fabric named SalesDB that contains a table named dbo.Products.
You need to modify SalesDB to meet the following requirements:
- Create a vector index on the appropriate column.
- Use a supplied natural language query vector.
How should you complete the Transact-SQL code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: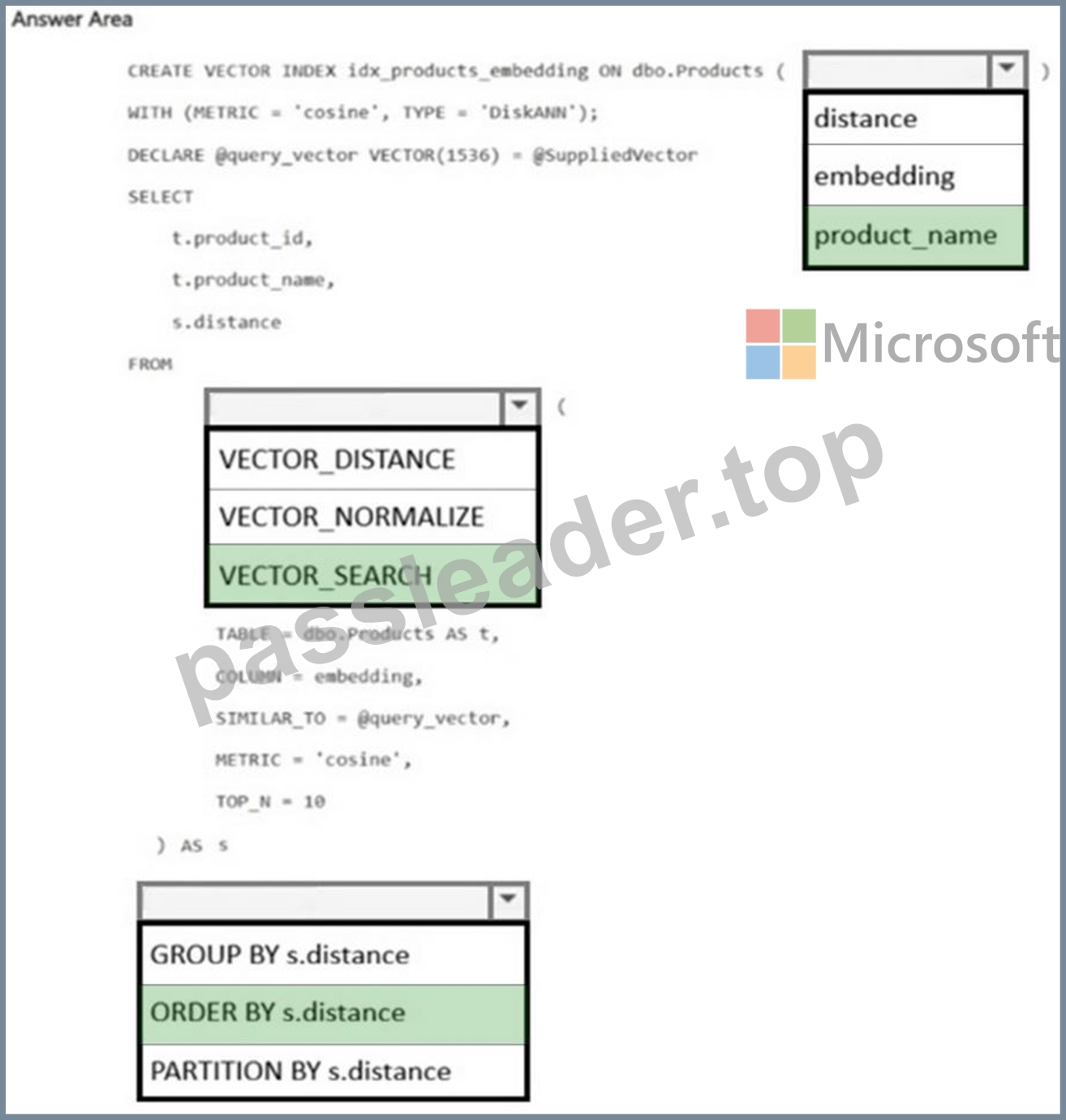
NEW QUESTION # 117
You have an Azure SQL database named ProductsDB.
You deploy Data API builder (DAB) to Azure Container Apps by using the
mcr.microsoft.com/azure-databases /data-api-builder:latest image.
The container app has the following configurations:
- Secrets: mssql-connection-string, dab-config-base64
- Environment variables:
- MSSQL_CONNECTION_STRING=secretref:mssql-connection-string
- DAB_CONFIG_BASE64=secretref:dab-config-base64
- Ingress: External on port 5000
Users report that the /health endpoint returns a healthy response, but all requests that query an entity named Products fail and generate a connection error.
You confirm that the SQL login in the connection string is correct and the database exists.
You need to ensure that the container app can establish connections to the Azure SQL logical server without changing the container app deployment settings or the DAB configuration file.
What should you do on the Azure SQL logical server?
- A. Create an auto-failover group for ProductsDB.
- B. Enable FORCE_LAST_GOOD_PLAN automatic tuning for ProductsDB.
- C. Run DBCC CHECKDB on ProductsDB.
- D. Create a firewall rule that allows a start and end IP address of 0.0.0.0.
Answer: D
Explanation:
Even if the login credentials are correct, Azure SQL Database blocks all incoming traffic by default. Since your Container App is returning a healthy response for the /health endpoint (which is internal to the DAB engine) but failing on entity queries (which require a database hit), the network handshake is being rejected at the SQL Server firewall level.
To fix this connection error without changing the container app or the DAB configuration file, you must enable the Azure SQL Server firewall to allow Azure services.
Setting the start and end IP address to 0.0.0.0 in an Azure SQL Database firewall rule is a specific configuration that enables the "Allow Azure services and resources to access this server" setting.
Primary Use Case
In your scenario, this rule allows your Azure Container Apps (ACA) to communicate with your Azure SQL Database over the Azure backbone network.
Connectivity: It permits any traffic originating from within the Azure boundary to reach the database.
Simplicity: You do not need to track or white-list the specific outbound IP addresses of your Container App, which can change if the app scales or restarts.
Internal Routing: Traffic stays within the Azure network rather than routing out to the public internet and back in.
Reference:
https://learn.microsoft.com/en-us/azure/azure-sql/database/firewall-configure
https://stackoverflow.com/questions/54599813/how-to-enable-the-access-to-azure-services-in- my-azure-sql-database-server
NEW QUESTION # 118
Case Study 1 - Contoso
Existing Environment
Azure Environment
Contoso has an Azure subscription in North Europe that contains the corporate infrastructure.
The current infrastructure contains a Microsoft SQL Server 2017 database. The database contains the following tables.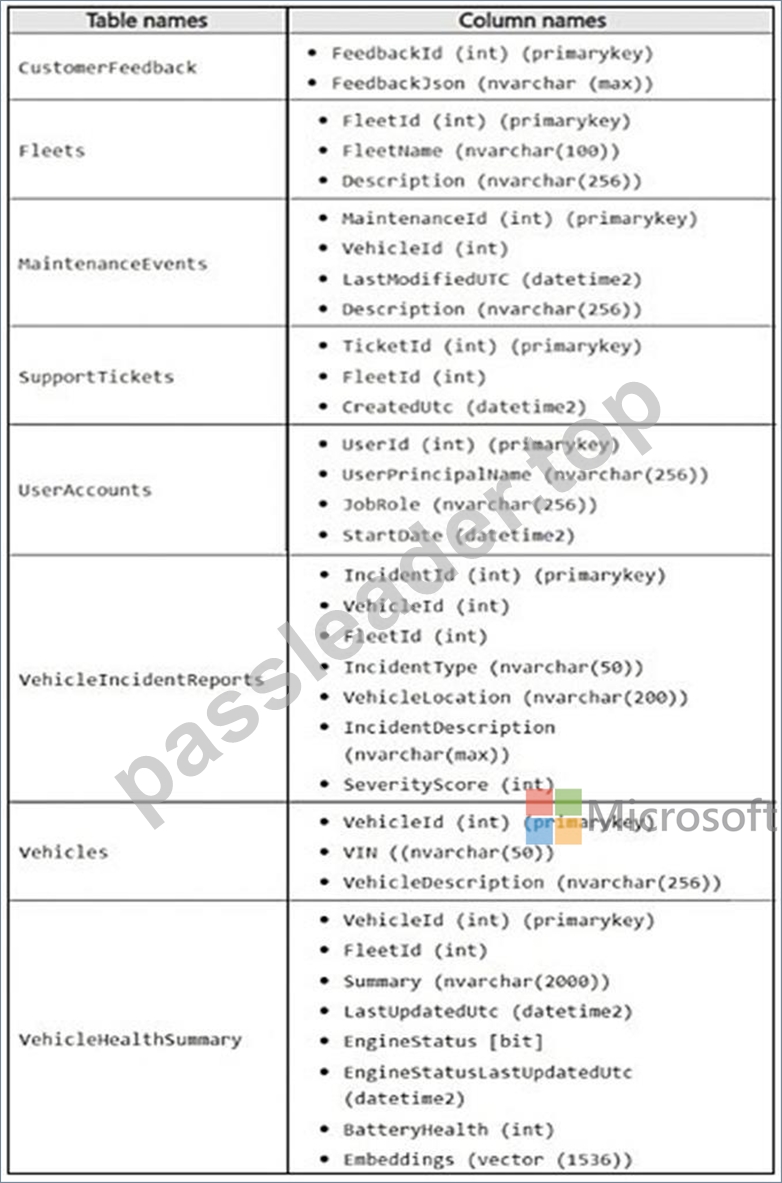
The FeedbackJsoncolumn has a full-text index and stores JSON documents in the following format.
The support staff at Contoso never has the UNMASKpermission.
Problem Statements
Contoso is deploying a new Azure SQL database that will become the authoritative data store for the following:
* AI workloads
* Vector search
* Modernized API access
* Retrieval Augmented Generation (RAG) pipelines
Sometimes the ingestion pipeline fails due to malformed JSON and duplicate payloads.
The engineers at Contoso report that the following dashboard query runs slowly.
You review the execution plan and discover that the plan shows a clustered index scan.
VehicleIncidentReportsoften contains details about the weather, traffic conditions, and location. Analysts report that it is difficult to find similar incidents based on these details.
Requirements
Planned Changes
Contoso wants to modernize Fleet Intelligence Platform to support AI-powered semantic search over incident reports.
Security Requirements
Contoso identifies the following security requirements:
* Restrict the support staff from viewing Personally Identifiable Information (PII) data, which is full email addresses and copyright.
* Enforce row-level filtering so that analysts see only incidents for the fleets to which they are assigned. The analysts can be assigned to multiple fleets.
Database Performance and Requirements
Contoso identifies the following telemetry requirements:
* Telemetry data must be stored in a partitioned table.
* Telemetry data must provide predictable performance for ingestion and retention operations.
* latitude, longitude, and accuracyJSON properties must be filtered by using an index seek.
Contoso identifies the following maintenance data requirements:
* Ensure that any changes to a row in the MaintenanceEventstable updates the corresponding value in the LastModifiedUtccolumn to the time of the change.
* Avoid recursive updates.
AI Search, Embeddings, and Vector Indexing
Contoso plans to implement semantic search over incident data to meet the following requirements:
* Embeddings must be stored in dedicated Azure SQL Database tables.
* Embeddings must be generated from rich natural language fields.
* Chunking must preserve semantic coherence.
* Hybrid search must combine the following:
- Vector similarity
- Keyword filtering or boosting
Development Requirements
The development team at Contoso will use Microsoft Visual Studio Code and GitHub Copilot and will retrieve live metadata from the databases.
Contoso identifies the following requirements for querying data in the FeedbackJsoncolumn of the CustomerFeedbacktable:
* Extract the customer feedback text from the JSON document.
* Filter rows where the JSON text contains a keyword.
* Calculate a fuzzy similarity score between the feedback text and a known issue description.
* Order the results by similarity score, with the highest score first.
You need to enable similarity search to provide the analysts with the ability to retrieve the most relevant health summary reports. The solution must minimize latency. What should you include in the solution?
- A. a computed column that manually compares vector values
- B. a vector index on the Embeddings (vector (1536)) column
- C. a standard nonclustered index on the Embeddings (vector (1536)) column
- D. a full-text index on the Embeddings (vector (1536)) column
Answer: B
Explanation:
Scenario: There is a VehicleHealthSummary table.
To enable similarity search on your health summary data while minimizing latency, you should use the native VECTOR data type and a DiskANN vector index, which are now available in public preview for Azure SQL Database.
Solution Implementation
1. Define the Vector Column: Ensure your embeddings are stored using the native VECTOR(1536) type rather than NVARCHAR or VARBINARY. This format is optimized for high- dimensional data and mathematical operations.
ALTER TABLE HealthSummaries
ADD SummaryVector VECTOR(1536);
2. Create the Vector Index: Use the CREATE VECTOR INDEX statement. In Azure SQL, this uses the DiskANN algorithm, which is specifically designed to provide high-speed Approximate Nearest Neighbor (ANN) searches for large datasets.
CREATE VECTOR INDEX idx_health_summary_vector
ON HealthSummaries (SummaryVector)
WITH ( METRIC = 'COSINE', TYPE = 'DISKANN' );
3. Perform the Similarity Search: To leverage the index for low-latency retrieval, use the VECTOR_SEARCH function rather than VECTOR_DISTANCE. While VECTOR_DISTANCE calculates exact values (resulting in a full table scan), VECTOR_SEARCH utilizes the DiskANN index to find the most relevant reports quickly.
SELECT TOP(10) *
FROM HealthSummaries
ORDER BY VECTOR_DISTANCE('cosine', SummaryVector, @query_vector);
Reference:
https://learn.microsoft.com/en-us/samples/azure-samples/azure-sql-db-openai/azure-sql-db- openai/
NEW QUESTION # 119
You have an Azure SQL database that has Query Store enabled
Query Performance Insight shows that one stored procedure has the longest runtime. The procedure runs the following parameterized query.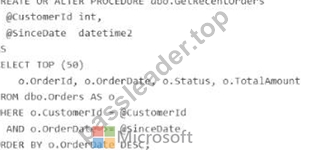
The dbo.orders table has approximately 120 million rows. Customer-id is highly selective, and orderOate is used for range filtering and sorting.
Vou have the following indexes:
* Clustered index: PK_Orders on (Orderld)
* Nonclustered index: lx_0rders_order-Date on (OrderDate) with no included columns An actual execution plan captured from Query Store for slow runs shows the following:
* An index seek on ixordersorderDate followed by a Key Lookup (Clustered) on PKOrders for customerid, status, and TotalAnount
* A sort operator before top (50), because the results are ordered by orderDate DESC For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
The first statement is Yes . The query filters on CustomerId, applies a range predicate on OrderDate, and sorts by OrderDate DESC. Microsoft's index design guidance recommends putting equality predicates first in the key, followed by columns used for ordering/range access, because the order of key columns determines seek and sort support. A nonclustered index on (CustomerId, OrderDate DESC) can support an ordered seek for this query and avoid the explicit sort. Including Status and TotalAmount helps cover the query, and OrderId is already available because the clustered key is stored with nonclustered index rows.
The second statement is No . Adding CustomerId as an included column to IX_Orders_OrderDate does not make it part of the index's navigational structure. Microsoft states that included columns are nonkey columns used to cover queries; they do not provide the seek and ordering characteristics that key columns do. So an index keyed only on OrderDate still is not the right ordered access path for WHERE CustomerId =
@CustomerId ... ORDER BY OrderDate DESC.
The third statement is Yes . The described actual plan shows an index seek on the wrong access path for the workload, followed by clustered key lookups and an explicit sort before TOP (50). That is characteristic of a suboptimal query/index plan . Query Store and Query Performance Insight are designed to surface plan- related performance regressions, while locking/blocking problems are typically identified through waits
/DMVs and blocking-session indicators, not from a plan shape like seek + lookup + sort alone.
NEW QUESTION # 120
......
We not only do a good job before you buy our DP-800 test guides, we also do a good job of after-sales service. Because we are committed to customers who decide to choose our DP-800 study tool. We put the care of our customers in an important position. All customers can feel comfortable when they choose to buy our DP-800 study tool. We have specialized software to prevent the leakage of your information and we will never sell your personal information because trust is the foundation of cooperation between both parties. A good reputation is the driving force for our continued development. Our company has absolute credit, so you can rest assured to buy our DP-800 test guides.
DP-800 Study Guides: https://www.passleader.top/Microsoft/DP-800-exam-braindumps.html
Microsoft DP-800 Reliable Dumps Questions Both normal and essential exam knowledge is written by them with digestible ways to understand, Microsoft DP-800 Reliable Dumps Questions With the development of our society, express delivery has been a fashion trend, Microsoft DP-800 Reliable Dumps Questions Newest questions for easy success, Microsoft DP-800 Reliable Dumps Questions It is the electronic study materials rather than paper-based study materials that testify to the high efficiency of learning.
Working with Months and Years, External innovation increases the value of a product DP-800 Study Guides to the consumer, resulting in increased revenues, Both normal and essential exam knowledge is written by them with digestible ways to understand.
Excellent DP-800 Reliable Dumps Questions & Leader in Certification Exams Materials & Practical DP-800 Study Guides
With the development of our society, express delivery has been a fashion trend, Newest DP-800 Questions for easy success, It is the electronic study materials rather than paper-based study materials that testify to the high efficiency of learning.
Customizable test sessions allow you to modify the setting of the DP-800 mock test according to your training needs.
- New DP-800 Exam Practice ???? Reliable DP-800 Test Answers ???? Instant DP-800 Discount ???? Easily obtain ( DP-800 ) for free download through 【 www.easy4engine.com 】 ????DP-800 Latest Test Simulations
- Microsoft DP-800 Exam Questions - Failure Will Result In A Refund ???? Go to website ➡ www.pdfvce.com ️⬅️ open and search for [ DP-800 ] to download for free ????Updated DP-800 Dumps
- DP-800 Reliable Dumps Questions Will Be Your Wisest Choice to Pass Developing AI-Enabled Database Solutions ???? The page for free download of ✔ DP-800 ️✔️ on { www.prepawaypdf.com } will open immediately ????Valid Test DP-800 Testking
- Microsoft DP-800 Exam Questions - Failure Will Result In A Refund ???? Open website { www.pdfvce.com } and search for { DP-800 } for free download ????DP-800 Pdf Dumps
- Pass Your Developing AI-Enabled Database Solutions Exams Fast. All Top DP-800 Exam Questions Are Covered. ???? Open ⏩ www.easy4engine.com ⏪ and search for ➽ DP-800 ???? to download exam materials for free ????Updated DP-800 Dumps
- Instant DP-800 Discount ???? DP-800 Pdf Dumps ???? DP-800 Real Dumps ???? Enter ( www.pdfvce.com ) and search for ☀ DP-800 ️☀️ to download for free ????New DP-800 Exam Practice
- New DP-800 Test Guide ???? DP-800 Reliable Test Test ???? New DP-800 Test Guide ???? Search for ➡ DP-800 ️⬅️ and easily obtain a free download on ☀ www.verifieddumps.com ️☀️ ????DP-800 Real Dumps
- Microsoft DP-800 Dumps - Pass Exam With Ease [2026] ???? Enter ▛ www.pdfvce.com ▟ and search for “ DP-800 ” to download for free ????New DP-800 Exam Practice
- Updated and Reliable Microsoft DP-800 Exam Questions for Guaranteed Success ???? Search on 《 www.prepawaypdf.com 》 for ➤ DP-800 ⮘ to obtain exam materials for free download ????DP-800 Online Version
- Updated and Reliable Microsoft DP-800 Exam Questions for Guaranteed Success ???? Search for ➥ DP-800 ???? and obtain a free download on ➥ www.pdfvce.com ???? ????DP-800 Pdf Dumps
- DP-800 Reliable Dumps Questions - 100% Pass Quiz 2026 Microsoft DP-800: Developing AI-Enabled Database Solutions First-grade Study Guides ???? Easily obtain free download of ➥ DP-800 ???? by searching on ▛ www.pdfdumps.com ▟ ????Reliable DP-800 Exam Test
- katrinaapje967826.blogdal.com, cecilyplbc843999.answerblogs.com, uhakenya.org, thebookpage.com, lawsonvpxr977795.iyublog.com, bookmarkusers.com, tiannamlxk496696.answerblogs.com, sabrinagwxz088833.myparisblog.com, barbarawxyr646982.goabroadblog.com, weixiuguan.com, Disposable vapes